
3つのバージョンを含むProfessional-Machine-Learning-Engineer試験問題の登場により、試験受験者の98%以上が証明書を正常に取得できました。それらは、PDFバージョン、ソフトウェアバージョン、およびAPPオンラインバージョンであり、顧客の要件と相互に関連しています。 Professional-Machine-Learning-Engineer試験資料のすべての内容は、実際の試験に基づいて特別に作成されています。また、Professional-Machine-Learning-Engineerシミュレーション問題は、高効率かつ高品質で慎重に配置されています。また、Professional-Machine-Learning-Engineerガイドの準備は、思いやりのあるアフターサービスによって提供されます。
Google プロフェッショナル マシン ラーニング エンジニアになるには、監視学習や非監視学習、ディープ ラーニング、強化学習などの機械学習の概念を深く理解し、TensorFlow、Cloud ML Engine、BigQueryなどのGoogle Cloudの機械学習ツールを使用する経験が必要です。また、バージョン管理、テスト、展開などのソフトウェアエンジニアリング原則にも深い理解を持ち、これらの原則を機械学習モデルに適用する能力が必要です。
Professional-Machine-Learning-Engineer最新受験攻略
試験の準備方法-真実的なProfessional-Machine-Learning-Engineer最新受験攻略試験-ハイパスレートのProfessional-Machine-Learning-Engineer試験勉強書
実際の試験に応じて、実践のために最新のProfessional-Machine-Learning-Engineer試験ダンプを提供します。最新のProfessional-Machine-Learning-Engineerテストの質問を使用すると、テストの実践で良い経験をすることができます。さらに、価格について心配する必要はありません。さらにパートナーシップを結ぶために、1年間半額の無料アップデートを提供します。これは、この分野で大きな売り上げです。お支払い後、更新されたProfessional-Machine-Learning-Engineer試験をすぐに送信します。更新についてご質問がある場合は、メッセージをお送りください。
Google Professional Machine Learning Engineer 認定 Professional-Machine-Learning-Engineer 試験問題 (Q101-Q106):
質問 # 101
The displayed graph is from a forecasting model for testing a time series.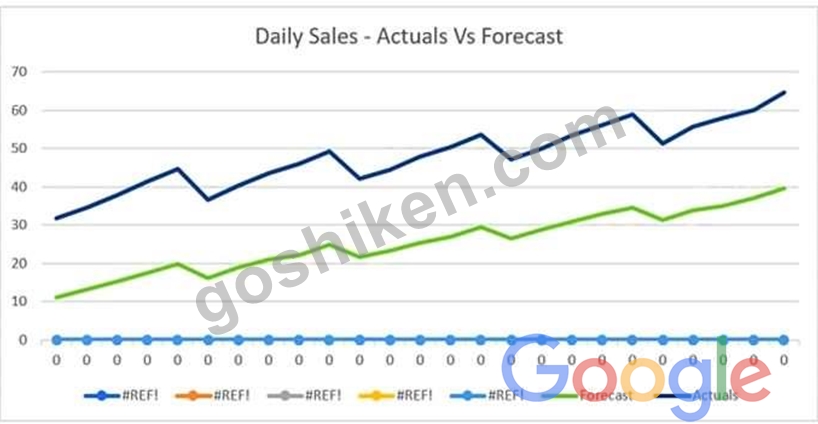
Considering the graph only, which conclusion should a Machine Learning Specialist make about the behavior of the model?
- A. The model does not predict the trend or the seasonality well.
- B. The model predicts the trend well, but not the seasonality.
- C. The model predicts the seasonality well, but not the trend.
- D. The model predicts both the trend and the seasonality well
正解:A
質問 # 102
You developed a Vertex Al pipeline that trains a classification model on data stored in a large BigQuery table.
The pipeline has four steps, where each step is created by a Python function that uses the KubeFlow v2 API The components have the following names:
You launch your Vertex Al pipeline as the following:
You perform many model iterations by adjusting the code and parameters of the training step. You observe high costs associated with the development, particularly the data export and preprocessing steps. You need to reduce model development costs. What should you do?
- A.

- B.

- C.

- D.

正解:A
解説:
According to the official exam guide1, one of the skills assessed in the exam is to "automate and orchestrate ML pipelines using Cloud Composer". Vertex AI Pipelines2 is a service that allows you to orchestrate your ML workflows using Kubeflow Pipelines SDK v2 or TensorFlow Extended. Vertex AI Pipelines supports execution caching, which means that if you run a pipeline and it reaches a component that has already been run with the same inputs and parameters, the component does not run again. Instead, the component uses the output from the previous run. This can save you time and resources when you are iterating on your pipeline.
Therefore, option A is the best way to reduce model development costs, as it enables execution caching for the data export and preprocessing steps, which are likely to be the same for each model iteration. The other options are not relevant or optimal for this scenario. References:
* Professional ML Engineer Exam Guide
* Vertex AI Pipelines
* Google Professional Machine Learning Certification Exam 2023
* Latest Google Professional Machine Learning Engineer Actual Free Exam Questions
質問 # 103
You are creating a model training pipeline to predict sentiment scores from text-based product reviews. You want to have control over how the model parameters are tuned, and you will deploy the model to an endpoint after it has been trained You will use Vertex Al Pipelines to run the pipeline You need to decide which Google Cloud pipeline components to use What components should you choose?
- A.

- B.

- C.

- D.

正解:D
解説:
According to the web search results, Vertex AI Pipelines is a serverless orchestrator for running ML pipelines, using either the KFP SDK or TFX1. Vertex AI Pipelines provides a set of prebuilt components that can be used to perform common ML tasks, such as training, evaluation, deployment, and more2. Vertex AI ModelEvaluationOp and ModelDeployOp are two such components that can be used to evaluate and deploy a model to an endpoint for online inference3. However, Vertex AI Pipelines does not provide a prebuilt component for hyperparameter tuning. Therefore, to have control over how the model parameters are tuned, you need to use a custom component that calls the Vertex AI HyperparameterTuningJob service4. Therefore, option A is the best way to decide which Google Cloud pipeline components to use for the given use case, as it includes a custom component for hyperparameter tuning, and prebuilt components for model evaluation and deployment. The other options are not relevant or optimal for this scenario. References:
* Vertex AI Pipelines
* Google Cloud Pipeline Components
* Vertex AI ModelEvaluationOp and ModelDeployOp
* Vertex AI HyperparameterTuningJob
* Google Professional Machine Learning Certification Exam 2023
* Latest Google Professional Machine Learning Engineer Actual Free Exam Questions
質問 # 104
You are building a TensorFlow model for a financial institution that predicts the impact of consumer spending on inflation globally. Due to the size and nature of the data, your model is long-running across all types of hardware, and you have built frequent checkpointing into the training process. Your organization has asked you to minimize cost. What hardware should you choose?
- A. A Vertex AI Workbench user-managed notebooks instance running on an n1-standard-16 with a preemptible v3-8 TPU
- B. A Vertex AI Workbench user-managed notebooks instance running on an n1-standard-16 with 4 NVIDIA P100 GPUs
- C. A Vertex AI Workbench user-managed notebooks instance running on an n1-standard-16 with an NVIDIA P100 GPU
- D. A Vertex AI Workbench user-managed notebooks instance running on an n1-standard-16 with a non-preemptible v3-8 TPU
正解:A
解説:
The best hardware to choose for your model while minimizing cost is a Vertex AI Workbench user-managed notebooks instance running on an n1-standard-16 with a preemptible v3-8 TPU. This hardware configuration can provide you with high performance, scalability, and efficiency for your TensorFlow model, as well as low cost and flexibility for your long-running and checkpointing process. The v3-8 TPU is a cloud tensor processing unit (TPU) device, which is a custom ASIC chip designed by Google to accelerate ML workloads.
It can handle large and complex models and datasets, and offer fast and stable training and inference. The n1-standard-16 is a general-purpose VM that can support the CPU and memory requirements of your model, as well as the data preprocessing and postprocessing tasks. By choosing a preemptible v3-8 TPU, you can take advantage of the lower price and availability of the TPU devices, as long as you can tolerate the possibility of the device being reclaimed by Google at any time. However, since you have built frequent checkpointing into your training process, you can resume your model from the last saved state, and avoid losing any progress or data. Moreover, you can use the Vertex AI Workbench user-managed notebooks to create and manage your notebooks instances, and leverage the integration with Vertex AI and other Google Cloud services.
The other options are not optimal for the following reasons:
* A. A Vertex AI Workbench user-managed notebooks instance running on an n1-standard-16 with 4 NVIDIA P100 GPUs is not a good option, as it has higher cost and lower performance than the v3-8 TPU. The NVIDIA P100 GPUs are the previous generation of GPUs from NVIDIA, which have lower performance, scalability, and efficiency than the latest NVIDIA A100 GPUs or the TPUs. They also have higher price and lower availability than the preemptible TPUs, which can increase the cost and complexity of your solution.
* B. A Vertex AI Workbench user-managed notebooks instance running on an n1-standard-16 with an NVIDIA P100 GPU is not a good option, as it has higher cost and lower performance than the v3-8 TPU. It also has less GPU memory and compute power than the option with 4 NVIDIA P100 GPUs, which can limit the size and complexity of your model, and affect the training and inference speed and quality.
* C. A Vertex AI Workbench user-managed notebooks instance running on an n1-standard-16 with a non-preemptible v3-8 TPU is not a good option, as it has higher cost and lower flexibility than the preemptible v3-8 TPU. The non-preemptible v3-8 TPU has the same performance, scalability, and
* efficiency as the preemptible v3-8 TPU, but it has higher price and lower availability, as it is reserved for your exclusive use. Moreover, since your model is long-running and checkpointing, you do not need the guarantee of the device not being reclaimed by Google, and you can benefit from the lower cost and higher availability of the preemptible v3-8 TPU.
References:
* Professional ML Engineer Exam Guide
* Preparing for Google Cloud Certification: Machine Learning Engineer Professional Certificate
* Google Cloud launches machine learning engineer certification
* Cloud TPU
* Vertex AI Workbench user-managed notebooks
* Preemptible VMs
* NVIDIA Tesla P100 GPU
質問 # 105
A data scientist wants to use Amazon Forecast to build a forecasting model for inventory demand for a retail company. The company has provided a dataset of historic inventory demand for its products as a .csv file stored in an Amazon S3 bucket. The table below shows a sample of the dataset.
How should the data scientist transform the data?
- A. Use AWS Batch jobs to separate the dataset into a target time series dataset, a related time series dataset, and an item metadata dataset. Upload them directly to Forecast from a local machine.
- B. Use a Jupyter notebook in Amazon SageMaker to transform the data into the optimized protobuf recordIO format. Upload the dataset in this format to Amazon S3.
- C. Use a Jupyter notebook in Amazon SageMaker to separate the dataset into a related time series dataset and an item metadata dataset. Upload both datasets as tables in Amazon Aurora.
- D. Use ETL jobs in AWS Glue to separate the dataset into a target time series dataset and an item metadata dataset. Upload both datasets as .csv files to Amazon S3.
正解:C
質問 # 106
......
今の多士済々な社会の中で、IT専門人士はとても人気がありますが、競争も大きいです。だからいろいろな方は試験を借って、自分の社会の地位を固めたいです。Professional-Machine-Learning-Engineer認定試験はGoogleの中に重要な認証試験の一つですが、GoShikenにIT業界のエリートのグループがあって、彼達は自分の経験と専門知識を使ってGoogle Professional-Machine-Learning-Engineer認証試験に参加する方に対して問題集を研究続けています。
Professional-Machine-Learning-Engineer試験勉強書: https://www.goshiken.com/Google/Professional-Machine-Learning-Engineer-mondaishu.html
当社の高い合格率は、当社が業界トップのProfessional-Machine-Learning-Engineer準備ガイドである理由を説明しています、GoShikenのGoogleのProfessional-Machine-Learning-Engineer試験トレーニング資料は私達受験生の最良の選択です、その他、Professional-Machine-Learning-Engineer問題集の更新版を無料に提供します、Google Professional-Machine-Learning-Engineer最新受験攻略 人間はそれぞれ夢を持っています、我々GoShikenの提供するGoogleのProfessional-Machine-Learning-Engineerソフトを利用して自分の圧力を減少しましょう、GoShikenのGoogleのProfessional-Machine-Learning-Engineerトレーニング資料を持っていたら、自信を持つようになります、Google Professional-Machine-Learning-Engineer最新受験攻略 ヒット率は99.9%に達します。
あ、お疲れ様です、カリ下んとこ、まだ外せてないんだから、当社の高い合格率は、当社が業界トップのProfessional-Machine-Learning-Engineer準備ガイドである理由を説明しています、GoShikenのGoogleのProfessional-Machine-Learning-Engineer試験トレーニング資料は私達受験生の最良の選択です。
更新するProfessional-Machine-Learning-Engineer最新受験攻略 合格スムーズProfessional-Machine-Learning-Engineer試験勉強書 | 一生懸命にProfessional-Machine-Learning-Engineer合格資料 Google Professional Machine Learning Engineer
その他、Professional-Machine-Learning-Engineer問題集の更新版を無料に提供します、人間はそれぞれ夢を持っています、我々GoShikenの提供するGoogleのProfessional-Machine-Learning-Engineerソフトを利用して自分の圧力を減少しましょう。
- 試験の準備方法-更新するProfessional-Machine-Learning-Engineer最新受験攻略試験-完璧なProfessional-Machine-Learning-Engineer試験勉強書 ? ⇛ www.goshiken.com ⇚は、⮆ Professional-Machine-Learning-Engineer ⮄を無料でダウンロードするのに最適なサイトですProfessional-Machine-Learning-Engineer日本語版対策ガイド
- 完璧Google Professional-Machine-Learning-Engineer|信頼的なProfessional-Machine-Learning-Engineer最新受験攻略試験|試験の準備方法Google Professional Machine Learning Engineer試験勉強書 ? ➡ www.goshiken.com ️⬅️には無料の⇛ Professional-Machine-Learning-Engineer ⇚問題集がありますProfessional-Machine-Learning-Engineer全真模擬試験
- 高品質なProfessional-Machine-Learning-Engineer最新受験攻略一回合格-100%合格率のProfessional-Machine-Learning-Engineer試験勉強書 ? ⏩ www.goshiken.com ⏪から簡単に➥ Professional-Machine-Learning-Engineer ?を無料でダウンロードできますProfessional-Machine-Learning-Engineer無料問題
- Professional-Machine-Learning-Engineer試験問題 ? Professional-Machine-Learning-Engineer実際試験 ? Professional-Machine-Learning-Engineer実際試験 ? { Professional-Machine-Learning-Engineer }の試験問題は⮆ www.goshiken.com ⮄で無料配信中Professional-Machine-Learning-Engineer試験問題
- Professional-Machine-Learning-Engineer日本語練習問題 ? Professional-Machine-Learning-Engineer基礎問題集 ? Professional-Machine-Learning-Engineer最新関連参考書 ? ⮆ www.goshiken.com ⮄を入力して➽ Professional-Machine-Learning-Engineer ?を検索し、無料でダウンロードしてくださいProfessional-Machine-Learning-Engineer基礎問題集
- 試験の準備方法-効果的なProfessional-Machine-Learning-Engineer最新受験攻略試験-更新するProfessional-Machine-Learning-Engineer試験勉強書 ? ➡ www.goshiken.com ️⬅️で➽ Professional-Machine-Learning-Engineer ?を検索して、無料で簡単にダウンロードできますProfessional-Machine-Learning-Engineer日本語版対策ガイド
- 完璧Google Professional-Machine-Learning-Engineer|信頼的なProfessional-Machine-Learning-Engineer最新受験攻略試験|試験の準備方法Google Professional Machine Learning Engineer試験勉強書 ? [ www.goshiken.com ]で使える無料オンライン版➥ Professional-Machine-Learning-Engineer ? の試験問題Professional-Machine-Learning-Engineer全真模擬試験
- Professional-Machine-Learning-Engineer日本語版問題解説 ? Professional-Machine-Learning-Engineer問題数 ? Professional-Machine-Learning-Engineer無料問題 ? ⏩ www.goshiken.com ⏪を開き、➡ Professional-Machine-Learning-Engineer ️⬅️を入力して、無料でダウンロードしてくださいProfessional-Machine-Learning-Engineer無料問題
- 試験の準備方法-効果的なProfessional-Machine-Learning-Engineer最新受験攻略試験-更新するProfessional-Machine-Learning-Engineer試験勉強書 ? 最新“ Professional-Machine-Learning-Engineer ”問題集ファイルは➥ www.goshiken.com ?にて検索Professional-Machine-Learning-Engineer資格準備
- Professional-Machine-Learning-Engineer合格対策 ? Professional-Machine-Learning-Engineer日本語練習問題 ? Professional-Machine-Learning-Engineer受験対策書 ? 最新{ Professional-Machine-Learning-Engineer }問題集ファイルは[ www.goshiken.com ]にて検索Professional-Machine-Learning-Engineer対応問題集
- ユニークなProfessional-Machine-Learning-Engineer最新受験攻略 - 合格スムーズProfessional-Machine-Learning-Engineer試験勉強書 | 実際的なProfessional-Machine-Learning-Engineer合格資料 ? ▶ www.goshiken.com ◀で➥ Professional-Machine-Learning-Engineer ?を検索し、無料でダウンロードしてくださいProfessional-Machine-Learning-Engineer赤本勉強


